- 0.はじめに
- 1.問題の概要
- 2.コンテスト時の最初の提出
- 3.コンテスト時間のほんの少しの改善
- 4.コンテスト時の複数の文字列を含む遷移ができてきたところ
- 5.コンテストの結果
- 6.復習開始
- 7.遷移確率行列と長さ100万の文字列の関係について
- 8.文字列の順番について
- 9.文字列のスコアの期待値の近似について
- 9.考察
- 10.AHCラジオを見る
- 11.確率を均等に割り振る
- 12.高速近似スコア計算で山登り
- 13.好ましさPが高い順に上位5個だけを考慮する
- 14.近似スコアの計算を修正
- 14.好ましさPの上位 3 文字列を bigram 集計して遷移行列を生成
- 15.wataさんの初期解を見る
- 16.上位2個を入れる
- 17.アルゴ式の問題を解く
- 18.ついにできた!本番24位相当
- 19.さらなる改善(本番17位相当)
- 19.終わりに
0.はじめに
はじめまして、もしくはお久しぶりです。競技プログラミング歴6年目のかえでです。
これは、2025年5月18日日曜日19時から23時までの4時間で開催された「トヨタ自動車プログラミングコンテスト2025#2(AtCoder Heuristic Contest 047)」の復習記事です。
本番では、1068人中446位という、前回とほぼ同じような結果で終わり、残念に思っています。コンテスト中は問題文の意味がわからず、最初の数時間を無駄にしてしまいました。
今はコンテストの翌日です。もう一度自分のやっていたことを振り返りつつ、再度解きなおしてみたいと思います。
追記:わかっていないところからのスタートなので、間違ったことや違和感のある表現がたくさん出てくるかと思います。突っ込みどころ満載の復習記事なので、正しさを気にする方は読まないように気をつけてください。また、書いてあることの真偽に関しては、自分で確かめるようお願いします。
1.問題の概要
- 目的
6 文字(a–f)だけを使う確率的文字列生成モデル LLM (Lovely Language Model) を設計し,与えられた好きな文字列 (36 個)が 部分文字列として1回以上出現する確率 を高め,期待好ましさ を最大化する。 - 状態数は
-
各状態 に文字 を割り当てる。
-
遷移確率行列 (整数%, 行ごとに合計100)。
-
生成は状態0から始め,文字列長 になったら停止。
- 文字列は互いに異なる6文字から12文字以下からなり、その数はN=36で固定
2.コンテスト時の最初の提出
コンテストが始まった後、問題文を読み、ビジュアライザを見ました。頭にAHC044が思い浮かび、苦手な種類の問題だなあと思いました。
すぐにChatGPTに問題文の要約を頼み、ACするコードを出力してもらいます。内容は、下記を実装したものでした。
- 最も好ましさ P が高い単語 T を繰り返す
開始数分で順位表を見ると、2043554というスコアが上位に並んでいました。100テストケースをまわした結果、平均が約12722で150倍する(150テストケースある為)と、2058300になります。提出をしないでも、このプログラムを提出しているのだなと思います。
しかし、このプログラムの意味が全くわかりませんでした。
問題文の意味がわからず、何を目指したらよいのかがわかりません。出力されている遷移確率行列が何を意味しているのかがわからず、また、スコアが何を計算していて、どのような値になるのかもわかりませんでした。
ビジュアライザを見たり、問題文を読み直したりしながら、このプログラムの表しているものを理解しようと努めます。
時間の経過とともに少しずつ意味がわかってきて、ああそうか、Pが高い文字列の順に遷移させればその文字列が出現するのだなあと思います。確かにこれは実装が簡単で良いなと思えたときには、コンテスト開始からすでに2時間が経過していました。
プログラムを提出します。無事ACして、2043554点を得ました。そのときの順位は150位でした。


3.コンテスト時間のほんの少しの改善
順位表のトップはすでに6650580です。1テストケースの平均は44337。はるか上の得点を見上げ、途方に暮れます。どうしてそんなことができるのか、全く予想がつきません。
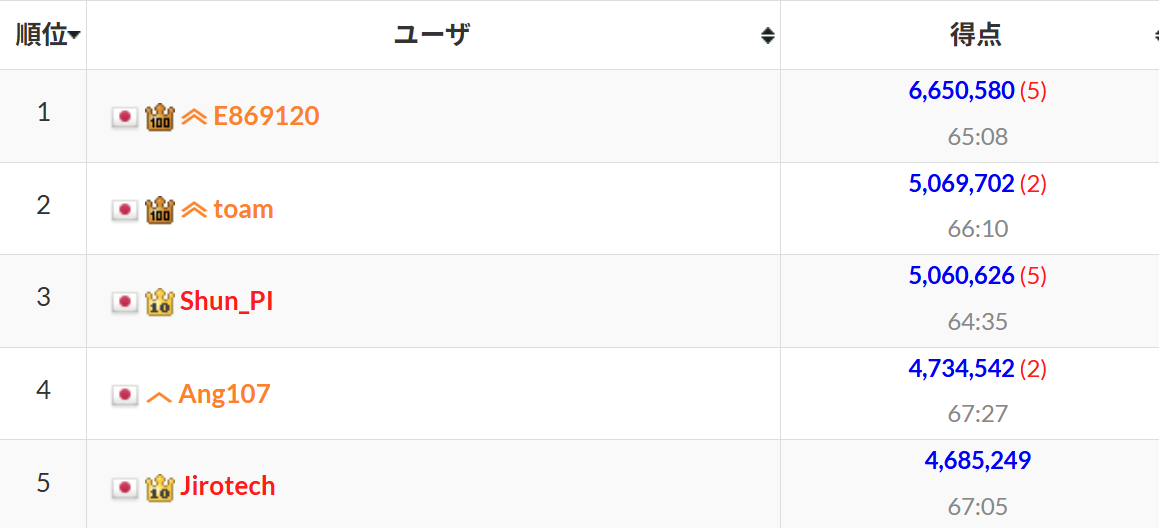
少しでもスコアを上げるために1個ではなく、複数の文字列が現れるようにすることを考えます。適当に詰め込むと複数の文字列になりますが、スコアの小さいもを複数足しても、最もPが高い1個には届きません。うまく重なる文字列があればとそれをつなげることを考えます。
下記を行った結果、ほんの少しだけスコアが良くなりました。(追記:下記はChatGPTに要約してもらったのですが、何をしているか自分でもわからない状態。)
本当に偶然同じ文字列があるときにだけ成功するといった状態で、100テストケースのうちのほんの数ケースで成功しただけでした。
1. P が高い語を 1〜4 個,最大オーバーラップで
長さ ≤12 の super-string R を生成
2. R の |R| 状態を「70 % forward / 30 % rand ハブ入口」
3. 残り状態を乱数クラスタ
(self 60 % / R 戻り 40 %)
4. 行列Aを出力
提出すると得点はほんの少し上がっただけでしたが、団子状の得点を抜け出すことができたので、青パフォになりました。


しかしその後得点を伸ばすことができずに提出できない時間が続きます。コンテスト開始から約3時間近く経過した21時50分には、順位が486位まで下がっていました。

4.コンテスト時の複数の文字列を含む遷移ができてきたところ
どうしたら複数の文字列が出現するのかを考えます。
同じ文字列が連続して出てくるときは1文字にして自己ループにすればよいと考え始めたところから、少しずつスコアがよくなっていきました。


しかし、少しよくなったところから、改善が進みませんでした。


やっと複数の文字列が含まれるようになってきたときには、時刻は22時16分になっていました。

- 重みの大きい単語が通る遷移に大きな確率を割り当てる
- a〜f が必ず 1 回ずつ含まれる 12 文字列を採用
- 行列初期化後に焼きなましで微調整
これを実装して提出すると、得点は2503892になりました。


そして、コンテストが終了しました。
5.コンテストの結果
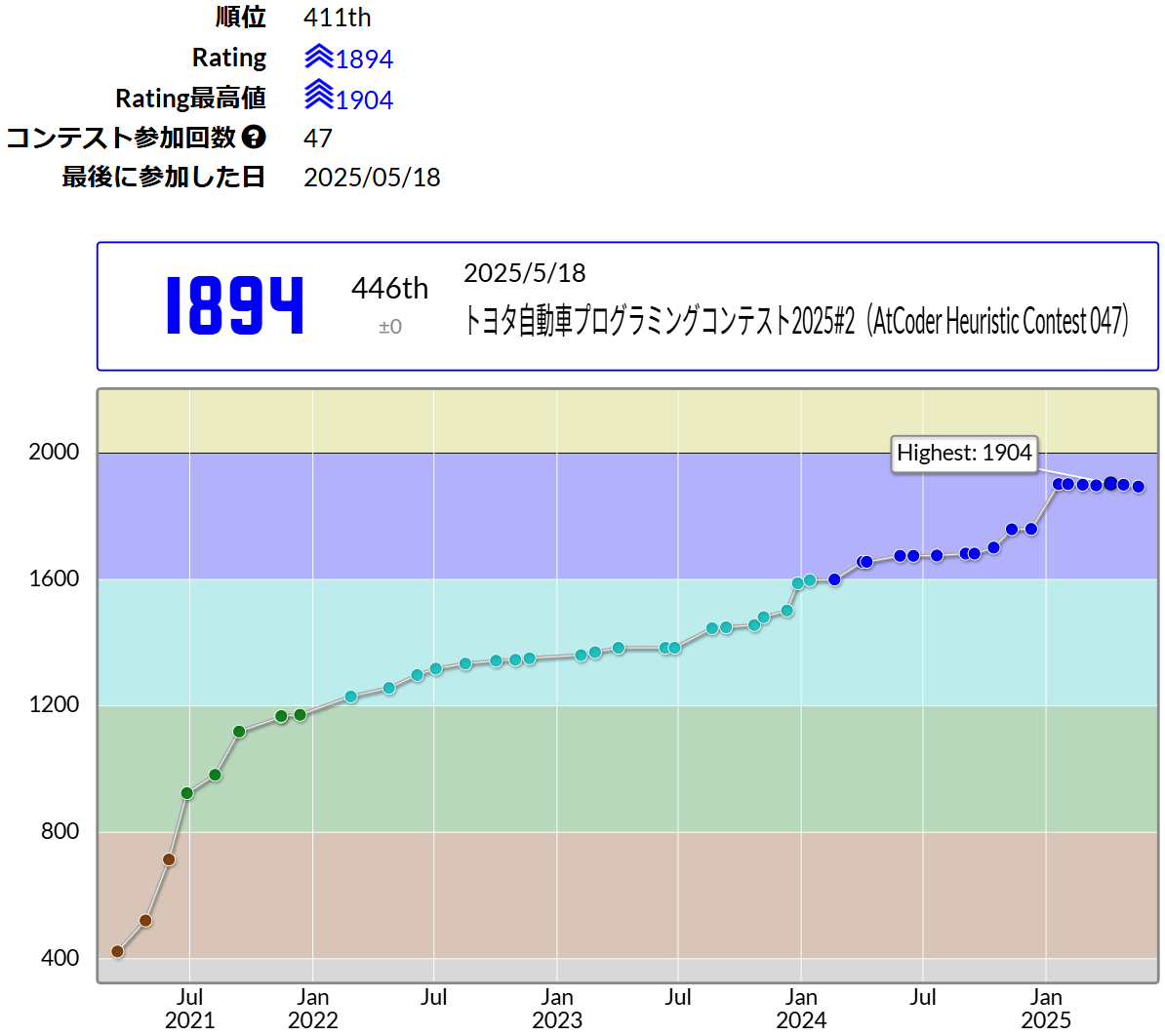
コンテストの結果は446位。パフォーマンスは1390でした。

時間減衰が入っている為、ヒューリスティックのRatingは前回の1900から6下がり、1894になりました。
6.復習開始
さて、何となく状態を変化させられるようになってきたところでコンテストが終了しましたので、あらためて自分が知りたかったことを調べます。
7.遷移確率行列と長さ100万の文字列の関係について
- 遷移確率行列・・・各状態間の遷移確率(合計100)を持つ行列で、M×Mの整数行列Aにおいて、A[i][j] は「状態 i から状態 j に遷移する確率(0~100 の整数、単位はパーセント)」を表す。
- 100万の文字列Lはある一定の割合に落ち着く。これを定常分布と言う。
- 行列累乗・・・「t回遷移したときの状態の確率分布」を求めるために使う。t回かけるとO(t)時間がかかり遅いので、O(logt)で求められる繰り返し二乗法を用いるとよい。
- 文字列の出現頻度を定常分布などで調整できる。
8.文字列の順番について
- どの文字がどの文字のあとに来るかは「遷移確率」に依存する。
- 状態数が多いときには複数のサイクルを混在させることができる。
9.文字列のスコアの期待値の近似について
- 「平均的に何回 Si が現れるか」が求められれば、スコアの期待値も近似できる。
- 期待スコア ≒ Σ [ Pi × E[#(Si の出現回数)] ]
- 式の言い換え:各好ましい文字列 Si が、生成された文字列の中に 何回出てくるかの期待値(=平均的な出現回数) に、重み Pi を掛けて全部足したものが、期待スコアである。
- 出現回数の期待値の近似
- 周期の場合は周期の長さで割る。
- 一般の場合(マルコフ連鎖)
- 遷移確率行列Aと定常分布πで簡易的に計算
9.考察
コンテスト終了後に他の人の解法で目にした定常分布や行列累乗、マルコフ連鎖や期待値の近似といった言葉が出てきます。わかったような、わからないような…。
うーん、難しい。
10.AHCラジオを見る
さて、コンテスト後の木曜日、2025年5月22日木曜日午後8時から、AHCラジオがありました。AHCラジオでは、wataさん、writerのchokudaiさんの2人がそれぞれ、わかりやすく説明してくれていて、やっと問題を理解しました。コンテスト中は、本当に問題文の意味が分かっていませんでした…。
やることもはっきりしました。
- 足して100になるように12文字の確率を均等に割り振る(8もしくは9になる)
- 長さが短い文字列は生成されるが、長いものが作られづらいので、スコアの高い長い文字列が作られるように重みをつける
- 焼きなましの試行回数が増やせるように、スコア計算は期待値の近似を使用する※10回程度行列累乗を行えば正しいスコア計算をしなくてもよい(定常分布のため)
11.確率を均等に割り振る
均等に割り振り、ビジュアライザで出力します。ああ、このビジュアライザを最初に見たかった。(追記:実はコンテスト時にも試していたのですが、スコアが悪かったため、ここからスタートするのをやめて、すぐに別の方法を探していました。)
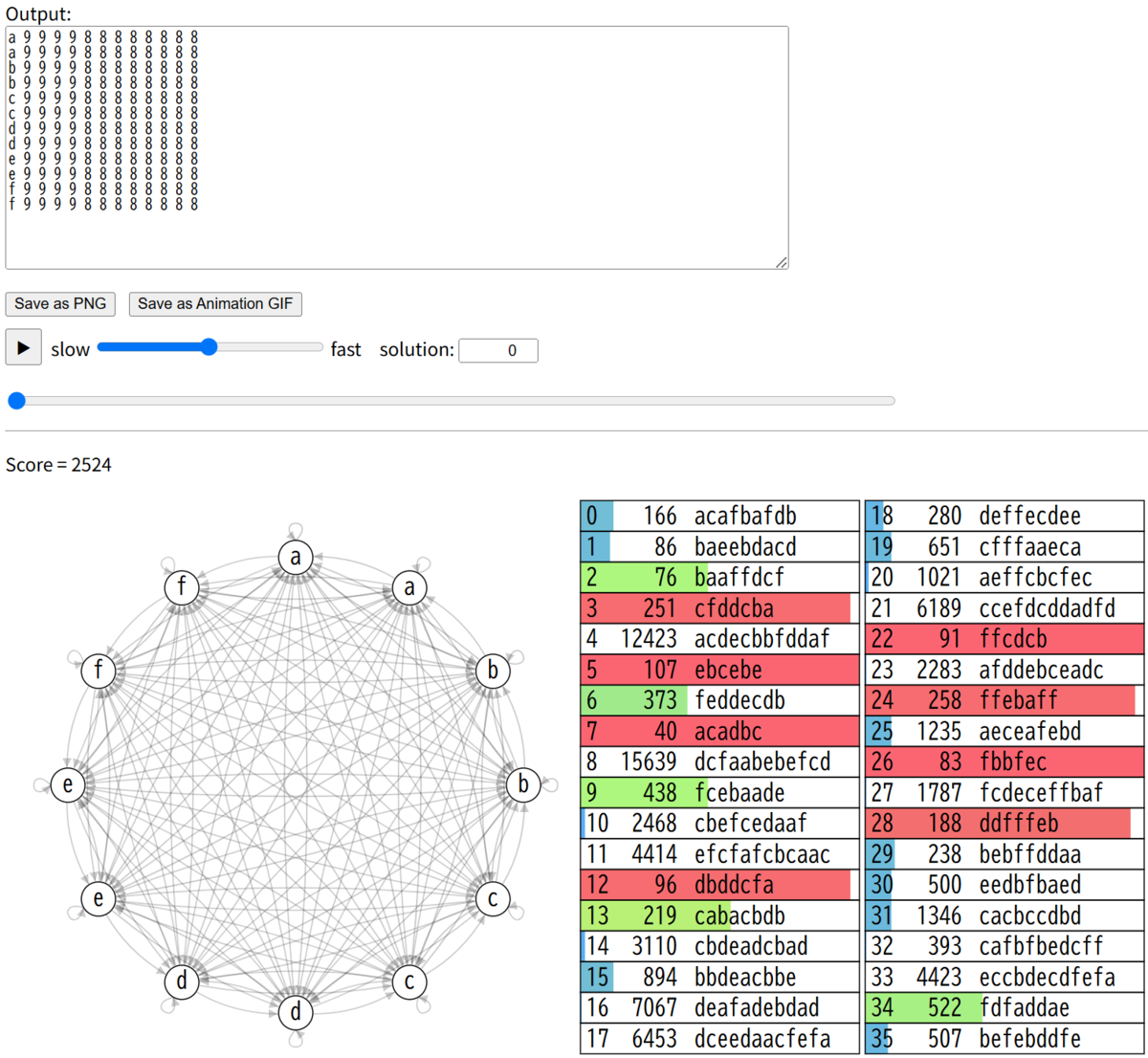
12.高速近似スコア計算で山登り
定常分布を元にした近似スコア計算で1.9秒山登りをします。試行回数は1万5千回ほど、seed0のスコアは2749になりました。
- ランダムで1行選んで、そのうちの2つを選んで+1、-1を行う
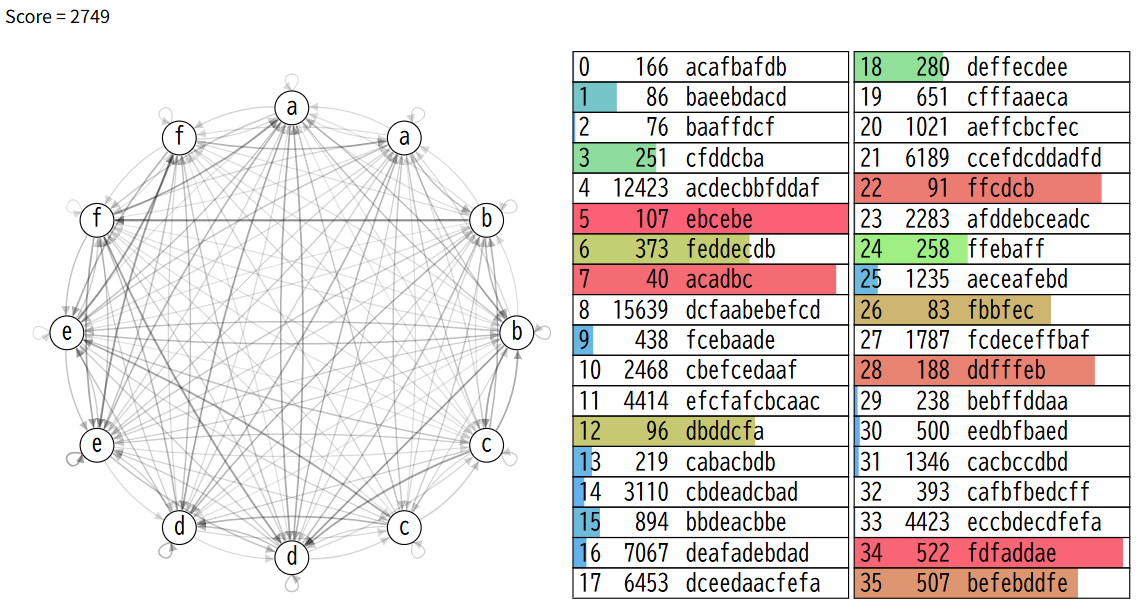
- 1から10の間でランダムに値を選んで、移動する

何か思ったほど上がらない…。
- 文字スワップ(と列の交換と行の交換)を入れる
上がりません…。
正しいスコアと近似スコアの差も気になります。
こんな感じ。
Time limit reached at iteration 17755
Exact Score : 2392.9427612334
Fast Score : 2746.2220796102
ChatGPTに投げると、近似スコア計算の修正を提案されます。
採用すると、大幅にスコアが伸びました。
Time limit reached at iteration 15823
Exact Score : 15671.8442342711
Fast Score : 15912.2094427280
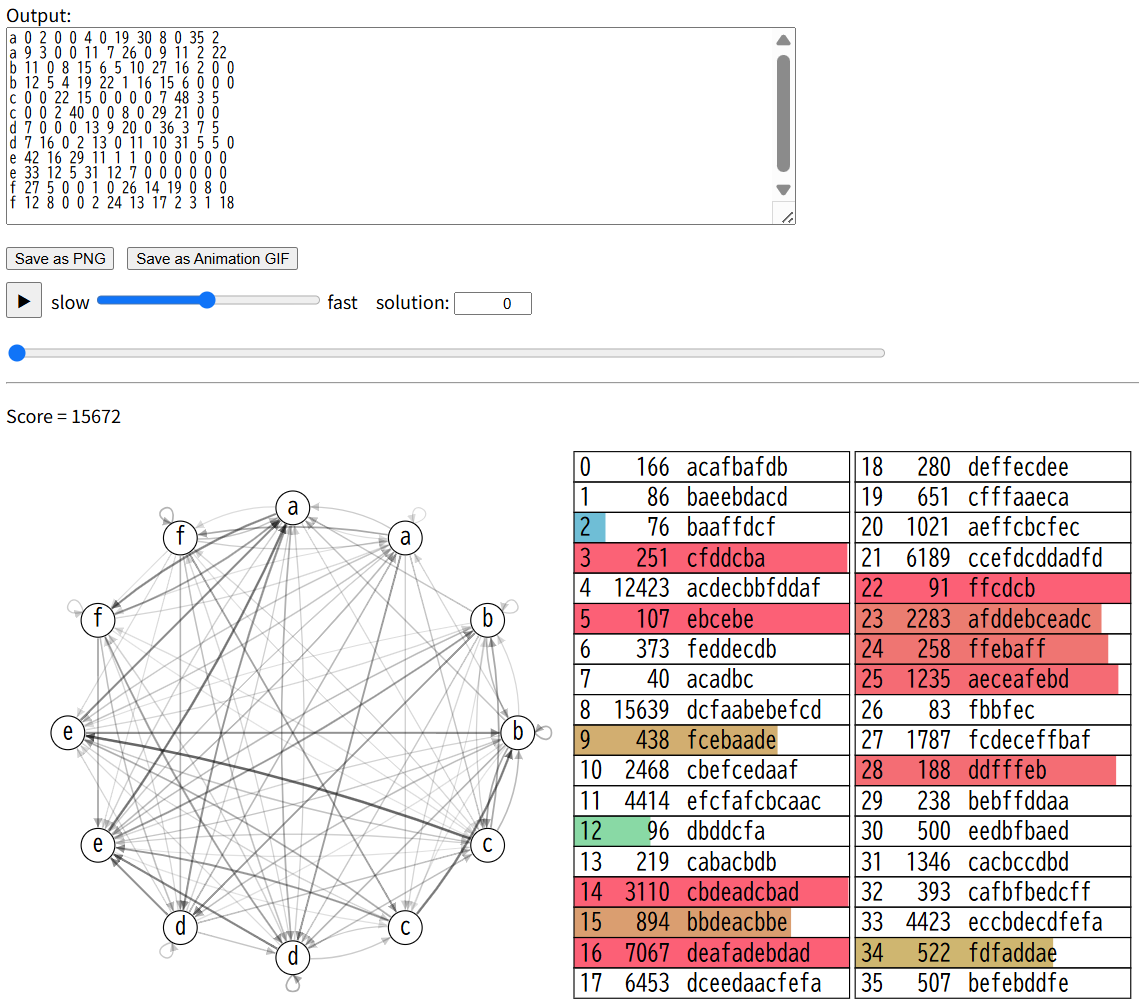
文字を独立に扱う近似から、連続2文字の遷移確率まで考慮する一次相関(一次マルコフ)近似に切り替えたことで、ヒット確率の過大評価が抑えられ、実際値との誤差がほぼ解消し、スコアが大きく伸びたということのようです。
うーん、難しい。
定常分布に従うとしても、それだけだと近似スコアにならないんだなぁ。
100テストケースの平均は11787。しかし、提出をするとTLEになりました。
何で?
コードを見直すと、正確なスコアを計算していたのが原因のようです。
その部分をコメントアウトし、もう一度提出します。
今度は無事ACしました。

ちなみに焼きなましにしたのですが、スコアがなぜか下がりました。
なぜ…。
13.好ましさPが高い順に上位5個だけを考慮する
先ほどのプログラムに重みづけをしたいと思いましたが、よくわからなかったので、最初から文字列を好ましさPが高い順に5個に絞って考慮することにします。
100テストケースの平均は16835になりました。提出すると2589131になり、コンテスト本番中の自分のスコアを超えました。

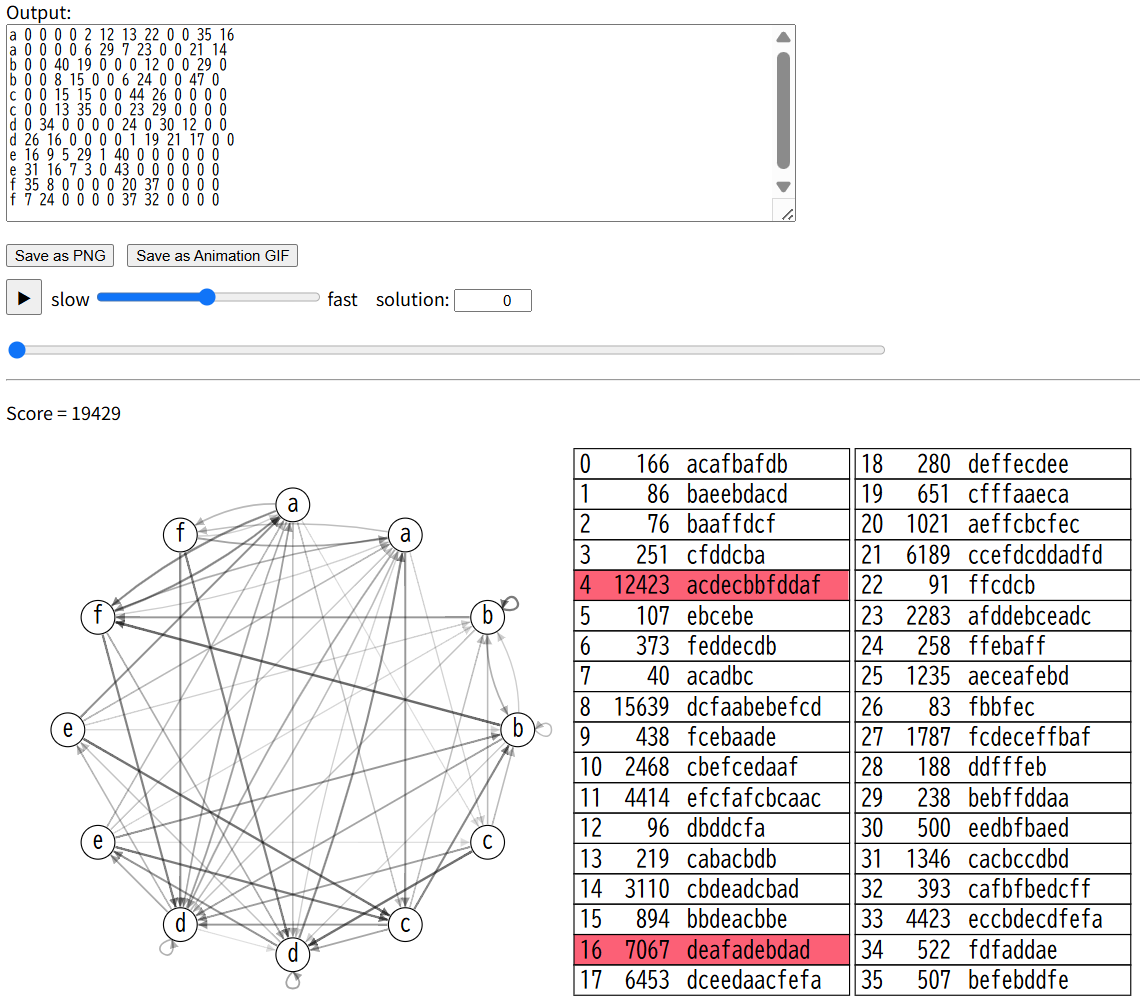
後日焼きなましにしたら、今度は少し上がりました。100テストケースの平均が17125になり、提出すると2645134になりました。

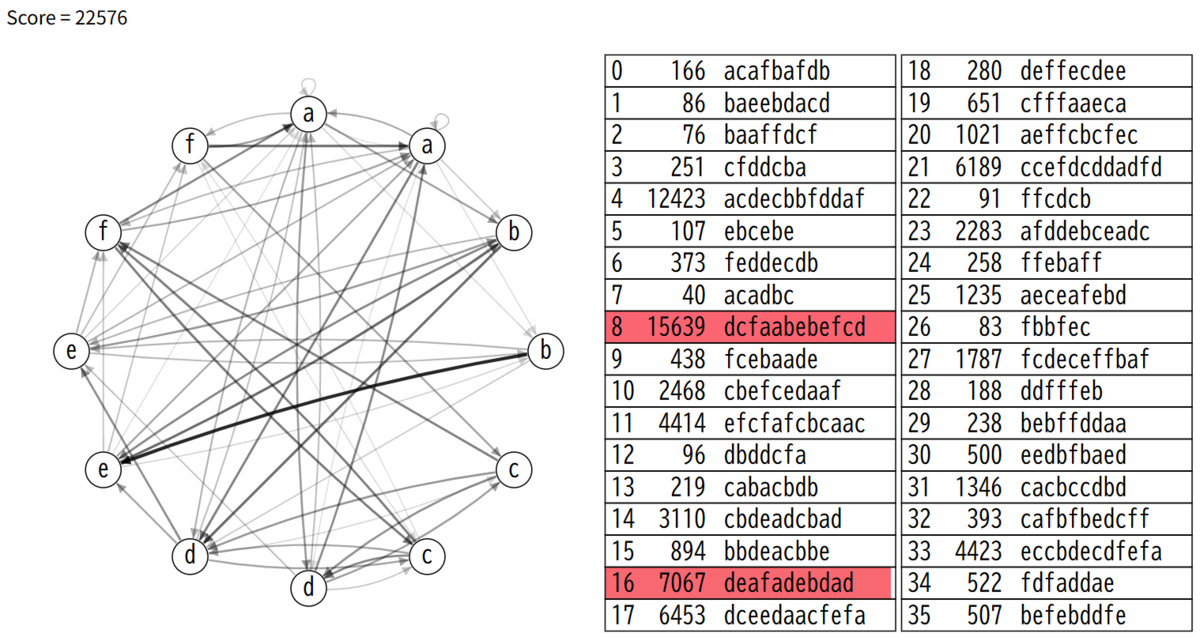
14.近似スコアの計算を修正
試行回数が3万回を超えるようになりました。
14.好ましさPの上位 3 文字列を bigram 集計して遷移行列を生成
解法を変えます。
- 得点が高い順で 上位 3 文字列 を取り出す
- 状態は abcdefabcdef の 12 状態 に固定
- 各文字列について 隣接 2 文字の出現回数をカウントし
- ただし 同じ文字が連続した場合は 2 番目を “後半 6 状態” 側に振る
- その総カウント行列を 行和=100 % になるよう正規化して遷移行列 A を作る
実行時間は2msで、100テストケースの平均は21073になりました。隣接2文字をbigram(バイグラム)と呼ぶとのこと。
bigram を数える=「どの 2 文字の並びがどれだけ現れたか」 を測ることで、その並びを 確率的に再現するマルコフ過程を作れるということでした。
すごい。
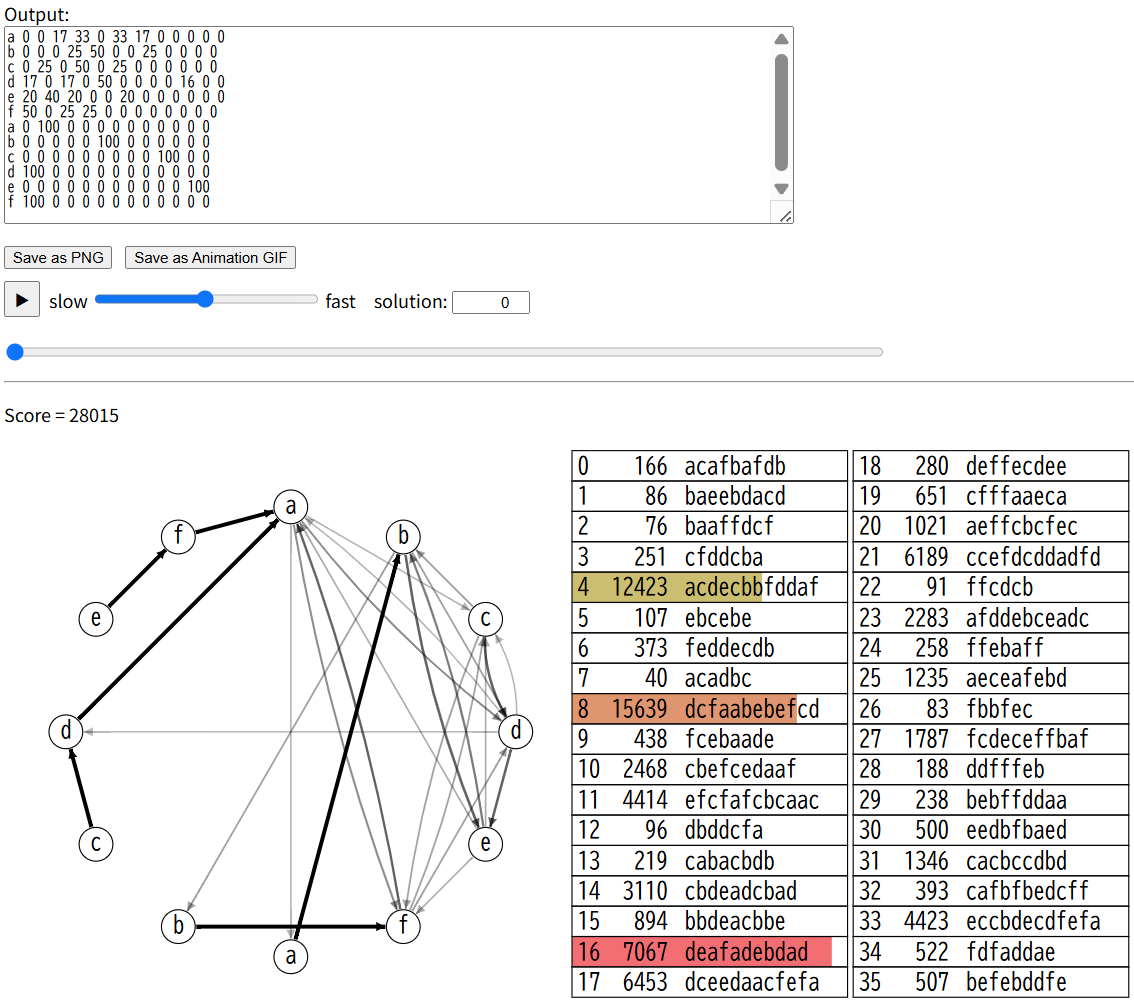
提出すると、本番356位相当の得点3117853になりました。

15.wataさんの初期解を見る
スコアを上げるために何をしたらよいかわからず、行き詰っています。
wataさんのコードをコードテストで出力し、seed0の解を出力します。seed0の初期解はScore=16512でした。

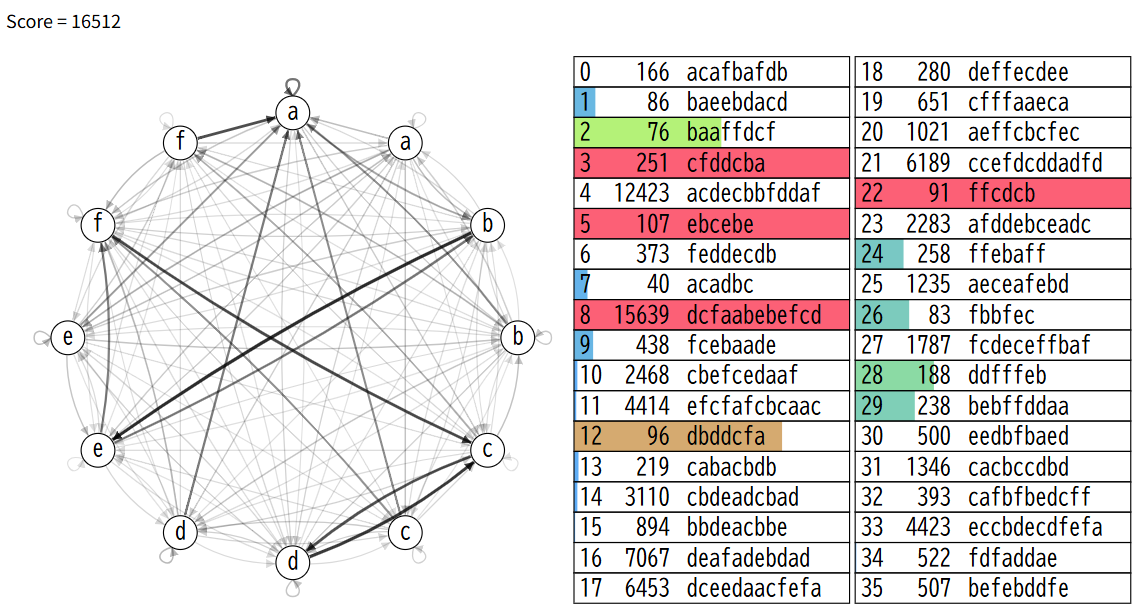
dcfaabebefcd (15639)にどのくらいの割合を割り振っているのかを見ます。
d→c : 66,3,7,5
c→f : 2,21,31,0
f→a : 5,3,58,4
a→a : 43,0,14,6
a→b : 24,7,13,1
b→e : 71,8,3,2
e→b : 42,1,2,11
b→e : 71,8,3,2
e→f : 38,1,2,9
f→c : 60,4,5,1
c→d : 57,3,8,9
16.上位2個を入れる
abcdefで1個、abcdefで1個遷移するようにして、上位2個が必ずできるようにします。
得点が0のものが複数のテストケースで出てきました。
使用しない文字があったときに0になっていました。
自己ループにならないようにします。
上位2個を入れることができました。100テストケースの平均は23791、提出すると3519309、本番291位相当の得点になりました。

17.アルゴ式の問題を解く
またも行き詰っています。
確率の勉強をし直す必要があるかもしれないと思って、アルゴ式の問題を36問解きました。プログラミングではなく、簡単な確率の問題が出題されています。1時間程度で解き終わりました。これなら解けました。
やっぱりAHCの問題って難しいのではないでしょうか。

18.ついにできた!本番24位相当
よくわからないなあとずっと思い続けてきたのですが、やっと解法が分かった気がします。今度こそ本当に。
- Lが100万と長いので、定常分布とみなすこと
- 行列Aを10回かけたものを定常分布の値として代用すること(10は適当な数。それほど大きい数でなくても近似する)
- 文字列が1回以上現れる期待値を求めること
- 文字列が長いものの方が出現率が低い(12文字だと(1/6)^12)ので、それを評価する方法を工夫する必要があること
ChatGPTに考えていることを伝えて、今あるプログラムの改善をお願いします。
そして、ついに4万点を超えました。
やっと、どういう問題だったのかがわかりました。
そして、問題がおもしろい!と思いました。
seed0では44911が出ました。

文字列を上位何個取るかを変えたり、確率を補正する値を変えて100テストケースを試します。上位の方の0.38乗という数字を見ていたのでそこから始めたのですが、上位何個かを取る場合、もう少し低い値の方がスコアがよくなりました。
提出をします。
結果は6177148点になり、本番24位相当のスコアになりました。


自分の書いたプログラムの内容です。
-
割り当て文字Cは「abcdefabcded」で固定
-
焼きなましの評価値
- 遷移行列Aを10回累乗し、定常分布の近似を取得
- 好ましさPが上位5個の文字列だけを評価対象とする
-
期待値DP で1回以上出現する確率を求める
- ポアソン近似で全体で1回以上の出現確率を高速に計算
- 出現確率 Qi を 0.25乗して補正(小さな値の切捨て防止)
- P[i] × Qi^0.25の合計を評価値とする
-
-
焼きなまし
-
繰り返し A[i][j1] -= d, A[i][j2] += d により A を改善
-
d は 1〜min(10, A[i][j1])
-
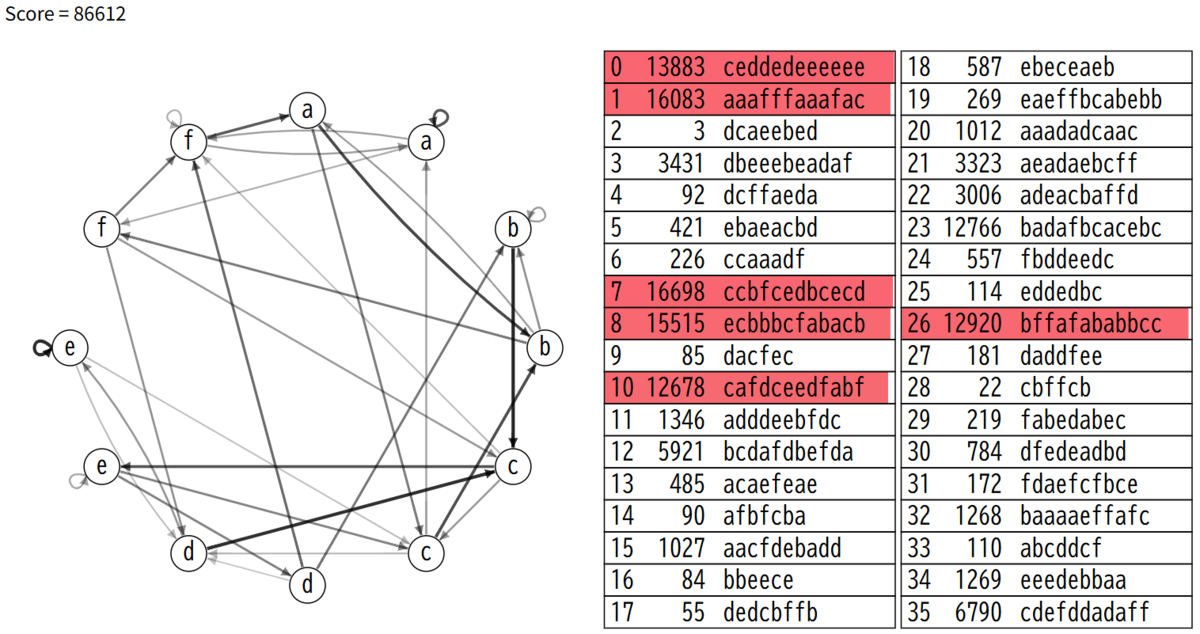
いろいろ試しているとき、一番スコアがよかったseed97では86612が出ていました。
19.さらなる改善(本番17位相当)
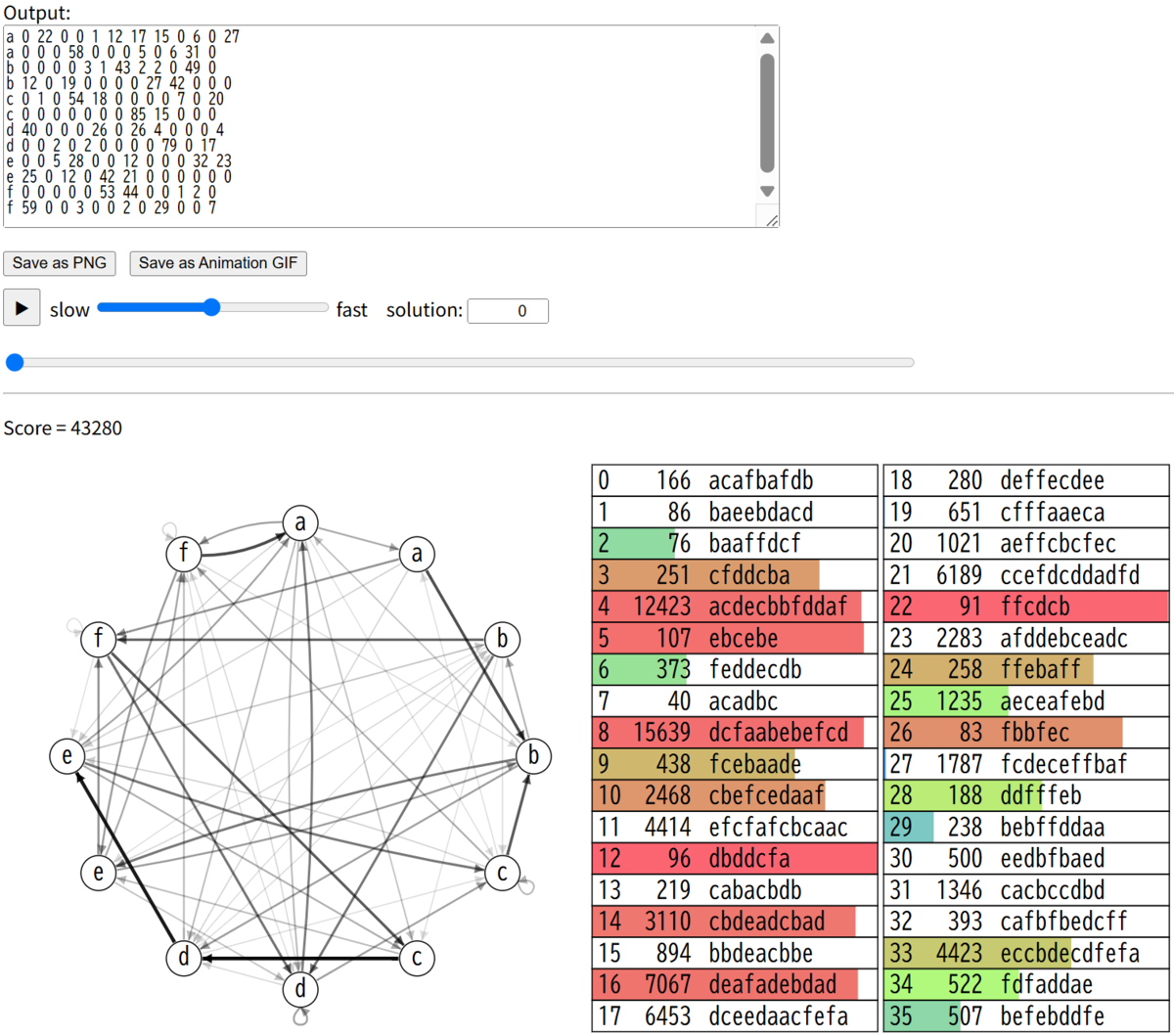
上位K個のKを決め打っていましたが、焼きなましでKを変動させるようにします。補正は0.38乗を使いました。
100テストケースでは42853平均に上がりました。
提出します。得点は6407513になりました。


19.終わりに
まだ改善できることはありそうなのですが、今回の復習はここで一旦終了したいと思います。
明日の午後7時からは、MC Digital プログラミングコンテスト2025(AtCoder Heuristic Contest 048)が始まります。
何とか復習が終わってよかった。
次こそ良い結果が出せますように。