- 0.はじめに
- 1.問題概要
- 2.最初の提出
- 3.考察
- 4.扉で邪魔をする
- 5.トップとの差を見る
- 6.コンテスト終了・結果
- 7.復習(キーワードのみで改善を試みる)
- 8.復習2(2026年6月28日更新)
- 9.復習3(指数スイッチ)
0.はじめに
はじめまして、もしくはお久しぶりです。競技プログラミング歴6年半のかえでです。
これは、2026年6月22日日曜日午後7時から11時まで開催された、4時間の短期コンテスト「AtCoder Heuristic Contest 067」の参加メモです。
トップのスコアには全く届いていないのですが、自分の振り返りとして参加時に考えていたことを書きたいと思います。
1.問題概要
- スイッチと扉を設置して、勇者が玉座にゴールするのができるだけ遅くなるよう移動距離を最大にする
- スイッチはK種類(K=10で固定)あり、スイッチiを押すたびに、対となる扉2iと2i+1の開閉状態が反転する
- 盤面はN×N(N=20 で固定)
- 扉の設置上限はM(M=50で固定)
2.最初の提出
ランダムで扉とスイッチを設置するACする解を提出。158212339点を得ます。
全く遠回りをさせることができず、最短でゴールに進んでいました。順位表には同じスコアが並びます。

3.考察
- 0から9までのスイッチを順に踏むように、スイッチを踏むと扉が開いて次のスイッチを踏めるようにする
- スイッチを壁側に置いて、扉をスイッチの前に設置する
- 2秒使って乱択。ベストを出力する
偶数番号のスイッチと奇数番号のスイッチが盤面の両端に来てできるだけ距離をかせぐ感じ。意味のない扉がまだいっぱい設置されていました。

4.扉で邪魔をする
ランダムよりは関節点を試した方がいいのかな。
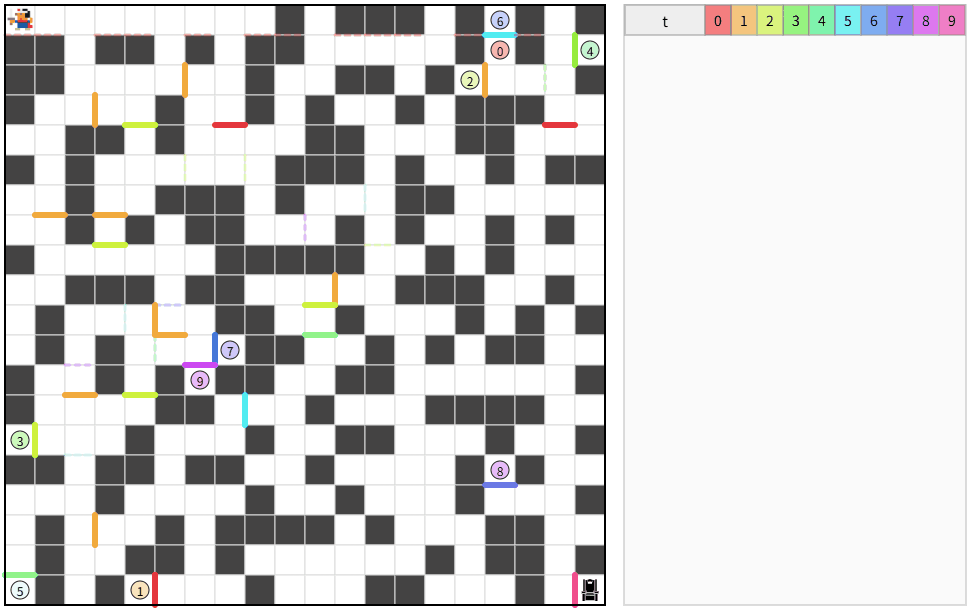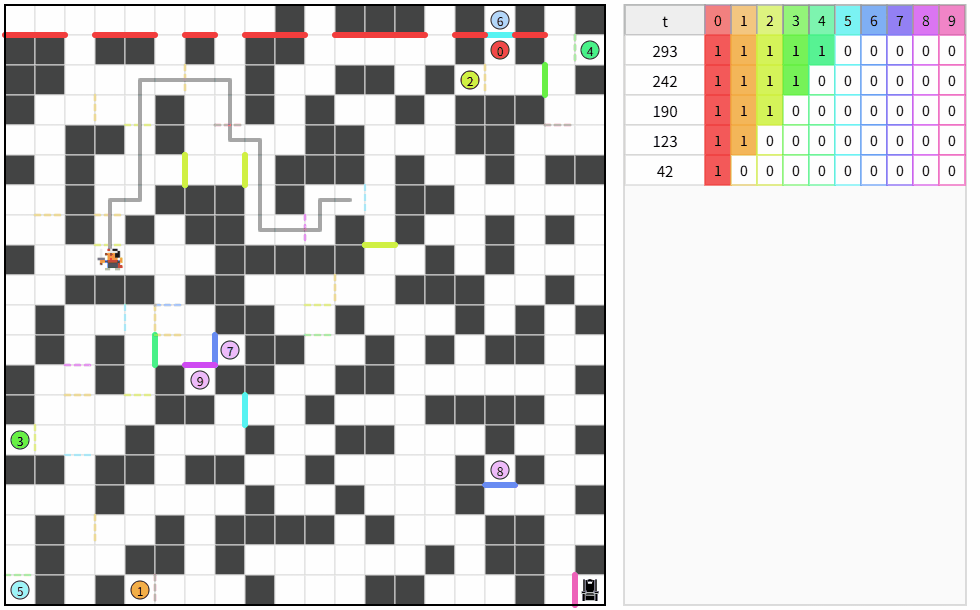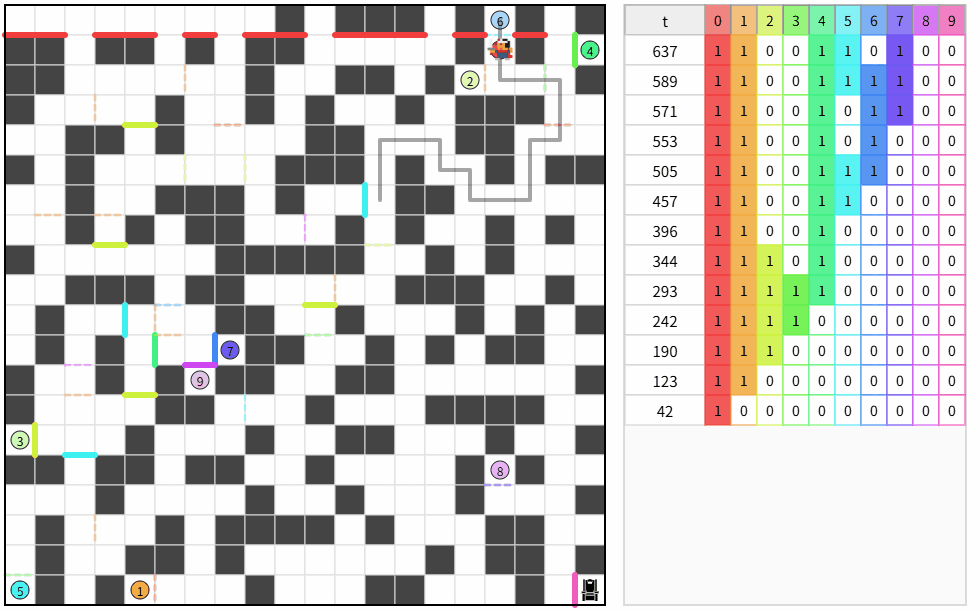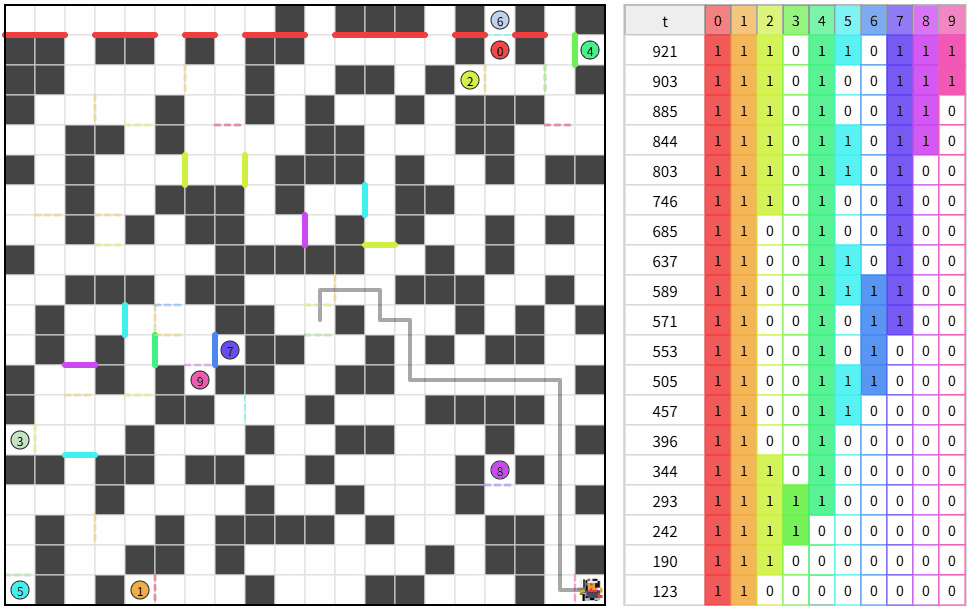
5.トップとの差を見る
自分の平均ターン数:約 1,360 ターン
トップの平均ターン数:約 49,180 ターン
うーん、差が大きすぎる。
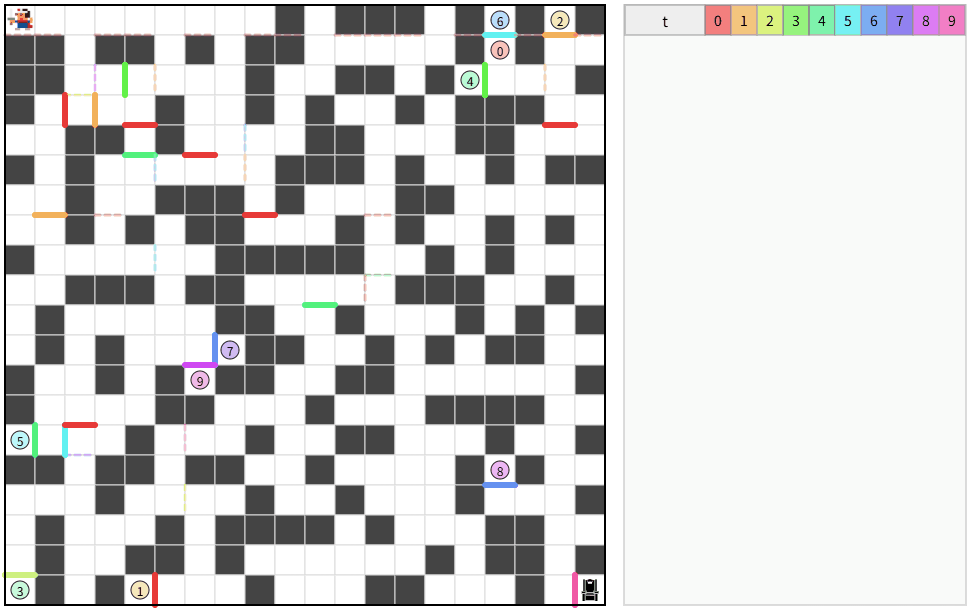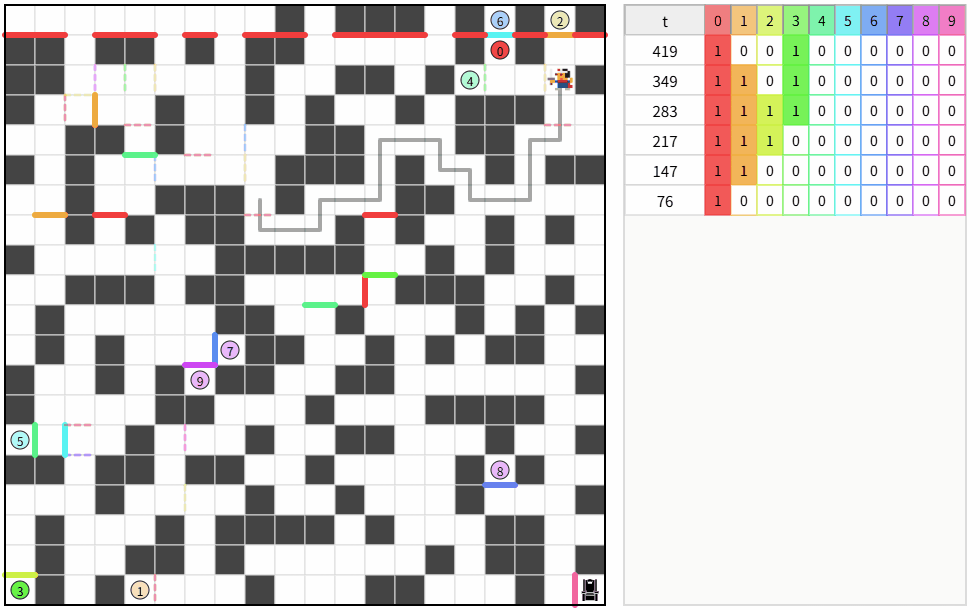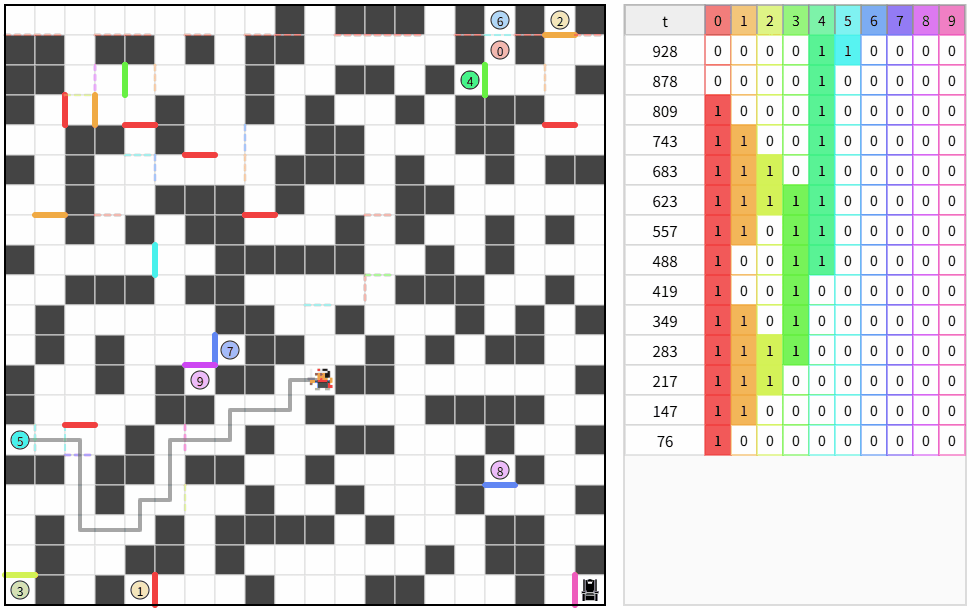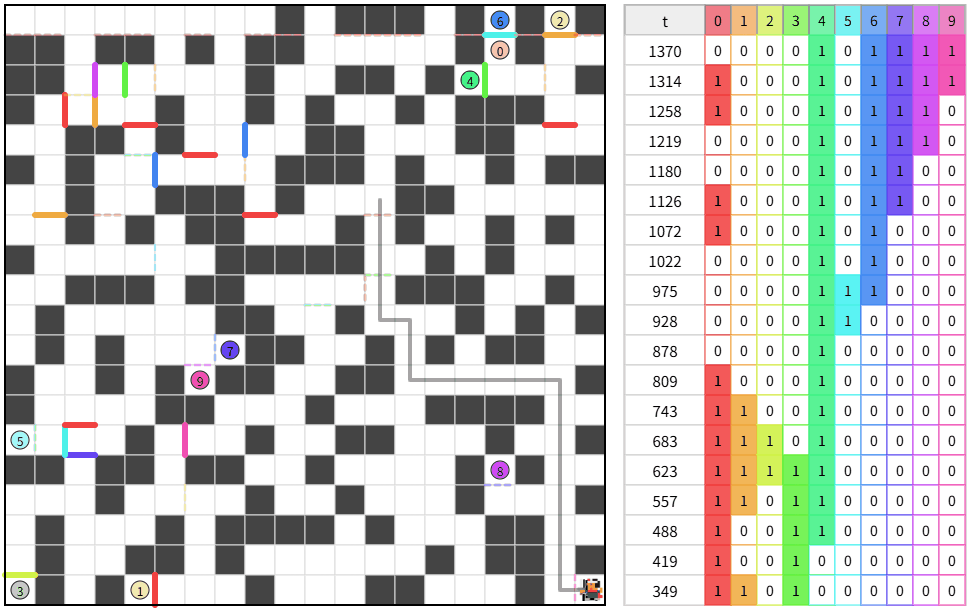
複数ループする解が偶然できた。
どうして?
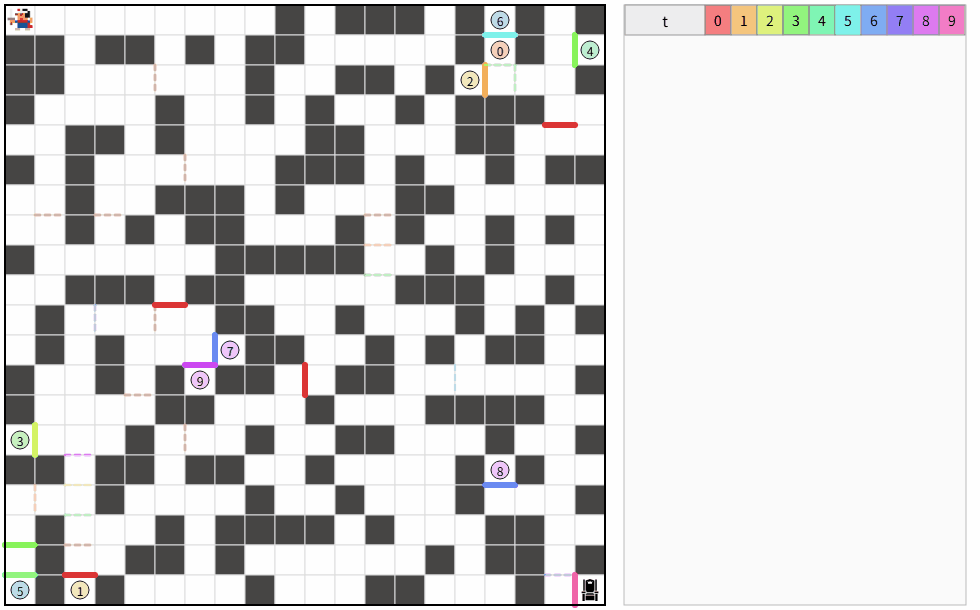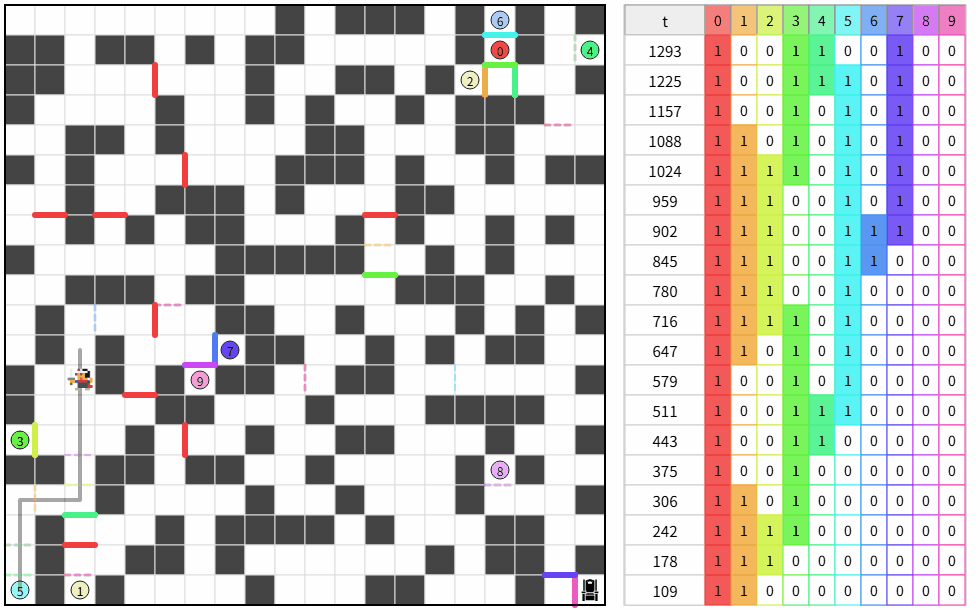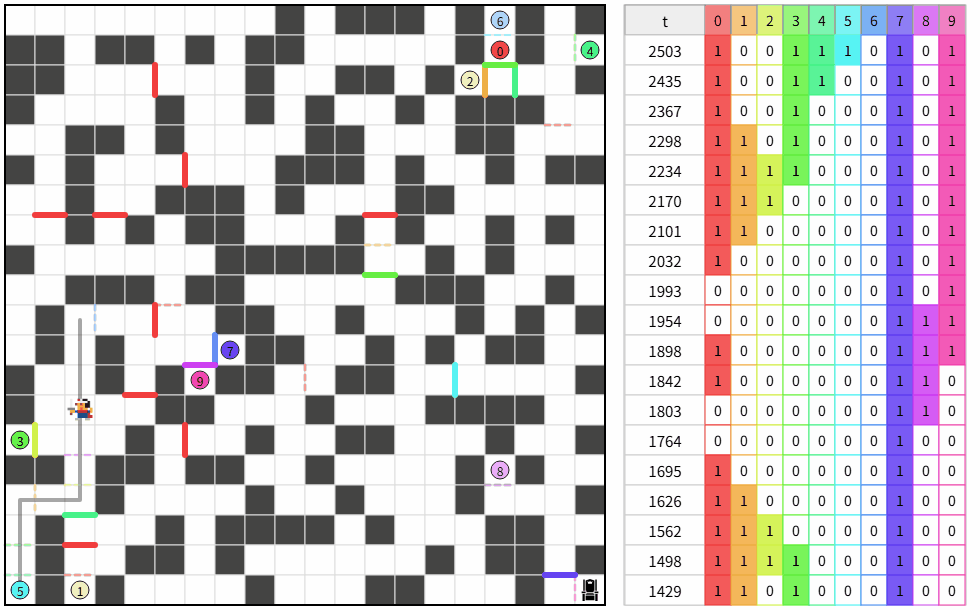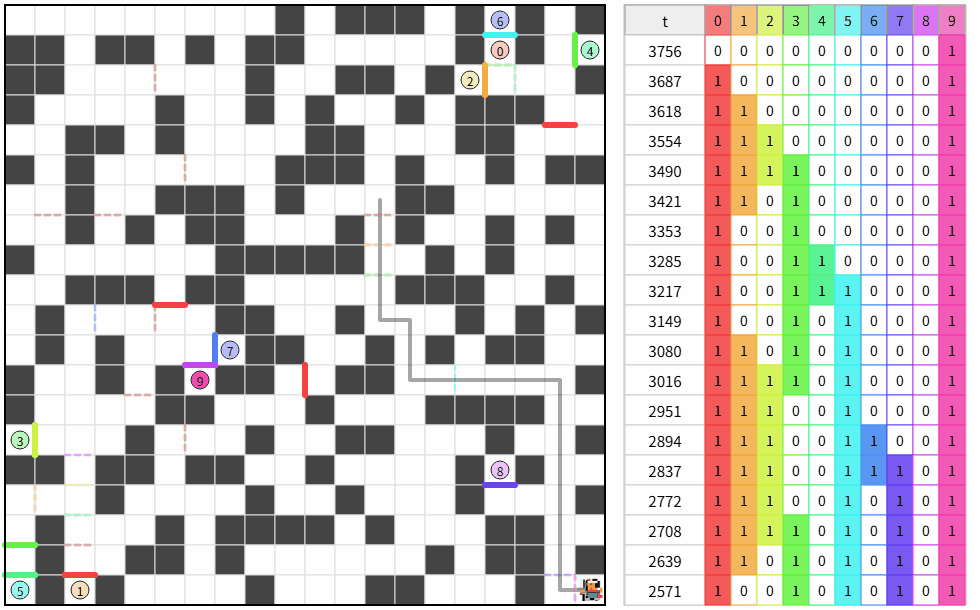
3枚扉が効いていそう。

トップの平均ターン数:約 63,500 ターン
トップとの差がどうしてこんなに開いているのかわかりません。
改善案を探すため、ビジュアライザを見る時間が続きます。
50個の扉を使い切っていなかったので、
- 余った扉を蛇行に使う
ことにします。少し上がりました。
6.コンテスト終了・結果
何もつかめないままコンテストが終了しました。
結果です。
得点は1,028,057,500点、順位は736人中263位、パフォーマンスは1578でした。
Ratingは時間減衰に負けて、前回より3下がり、2209になりました。

7.復習(キーワードのみで改善を試みる)
さて、コンテスト翌日です。気を取り直して復習をします。
Xではコンテスト終了後に、聞き慣れない「9連環」、「グレイコード」というキーワードが飛び交っていました。キーワードを元にコードを改善します。
まずは「9連環」解法に取り組みます。
10連環は55枚必要とのことで、扉の数の上限50枚では足りません。9連環は45枚でできるということだったので、9連環を作ります。
100テストケースを試すと、できたりできなかったりします。seed70ではスコア10079285が出ていましたが、平均は3936377とイマイチです。
そこで、できなかったときには、コンテスト中に使っていた貪欲解を使用することにします。平均は8045151になりました。
提出をします。本番188位相当のスコア、1,256,058,730が出ました。パフォーマンスは1753相当です。

スイッチを一個使っていないのがもったいないので、扉を共有することで10連環にできないかを試します。
seed0ではスコア9787739が出ました。17678ターンです。

実行制限時間を20秒に伸ばしてみると、100テストケースのスコアは、835万平均から875万平均に上がりました。高速化を行います。
少し良くなりました。

「グレイコード」解法だと結果が変わるのでしょうか。maskを使って評価します。
100テストケースの平均は863万になりました。
実行時間を20秒に伸ばしてスコアを見ます。100テストケースの平均は893万になりました。とはいうものの、これを2秒におさめる方法がわかりません。
ここまでやってきて、ふと、上のビジュアライザに目をやります。
あ、と思いました。
勇者が通らないルートに扉を置いていました。一番上の左半分です。
意味がないですね、これ。
修正を試みますが、思ったようにうまくいきません。
それでも少し改善したのでプログラムを提出します。結果は少し良くなって本番169位相当の得点が出ました。

100テストケースで一番良いスコアはseed37の10536830、29712ターンでした。

出力を見ると、扉がまだ余っていました。
まだまだ改善できそうなものの、そろそろ寝たいと思います。
というわけで、一旦ストップして、復習の続きはAHCラジオを見た後に行いたいと思います。
一晩寝て起きたら、適当なことをやっている気がしてきました。AHCラジオを見た後にちゃんと復習します。
8.復習2(2026年6月28日更新)
AHCラジオを見て、自分がよくわかっていなかった部分について少しわかったかもしれません。
復習をしていて、扉が足りないと思っていたのは、下図の左の構造を盤面に作ろうと思っていたからでした。
図の右のような木を作ると、扉の数の必要数は19個です。設置できる扉の上限は50なので、実は扉がたくさん余ります。余った扉を使用して最短ルートを遠回りにすれば、さらに高いスコアを出せるようになります。

というわけで、実装してみましょう(実装はLLMに依頼)。
悪戦苦闘の末、やっとseed0で56351ターン、スコア11460225の解ができました。

さらに試すと63519ターン、スコア11632972の解ができました。

とはいうものの、100テストケースの平均は840万くらいで、自己ベストを更新するにはあと少し足りなそうです。扉とスイッチをセットで動かすと良い場所に移動しやすい模様。
余った扉でショートカットをふさぐと857万平均に。
ここまでやってきたものの時間がなくなったので、今日はここまでにしたいと思います。
9.復習3(指数スイッチ)
seed0では1100万スコアを超えましたが、他のテストケースではなかなかうまくいきませんでした。理由は、
- 戻れる別の道(ショートカットになる道)をふさぐことができていなかったこと
- スイッチ0と他のスイッチの距離が近いものができあがってしまうこと
です。
- 玉座側からスイッチ9、スイッチ8、…スイッチ1と配置します
- 同じ枝にならないようにスイッチを配置します
やっと他のテストケースもよくなってきて、平均934万まで上がりました。
提出をすると本番155位相当の得点が出ました。

まだ扉は余っています。
- 使っていないエリアへの迂回路を余った扉で作る
seed0のスコアは11733545になりました。

そろそろ上位の方のプログラムを見に行こうかな。